本文介绍 Translate Document Quick Action,一个可以从 Finder 调用的 Mac 文档翻译工具,支持 PDF、Word、Markdown、TXT、图片 OCR 和音视频转录文本。
我开源了一个新的小工具:Translate Document Quick Action。
项目地址在这里:Jingyuan-Zheng/translate-document-quick-action。
它最初是一个 macOS Finder Quick Action:选中文档,右键运行,就在原文件旁边生成翻译后的文件。后来我把核心逻辑整理成了普通 Python 脚本,所以它也可以从命令行使用。
为什么要做这个工具
实际工作里的“翻译文档”很少只有一种格式。
今天可能是 PDF 报告,明天是 Word 文档,后天又变成 Markdown 笔记、截图、扫描图,甚至是一段会议录音,需要先转录再翻译。
很多工具只能解决其中一小段流程。Translate Document Quick Action 想解决的是更日常的问题:尽量把这些常见文件格式放进同一个入口里,让你不用每次都临时找工具、改脚本、搬文件。
支持哪些格式
目前项目支持:
- PDF:通过
pdf2zh-next翻译 - DOCX:直接修改 Word XML,尽量保留原始包结构和媒体引用
- Markdown:保护常见 Markdown 结构后翻译
- TXT:按行保留文本结构
- 图片:可使用 macOS Vision OCR 的轻量方案,或接入
manga-image-translator - 音频和视频:通过 MacWhisper 的
mwCLI 生成转录文本,并可继续翻译转录稿
输出文件会生成在原文件旁边,并且不会覆盖已有文件。单语译文会使用目标语言后缀,例如 _CN.docx;双语文件会使用源语言和目标语言后缀,例如 _EN_CN.docx。
翻译效果预览
PDF 双语输出使用 pdf2zh-next 的双语 PDF 模式,适合对照检查原文和译文,也尽量保持页面布局的可读性。
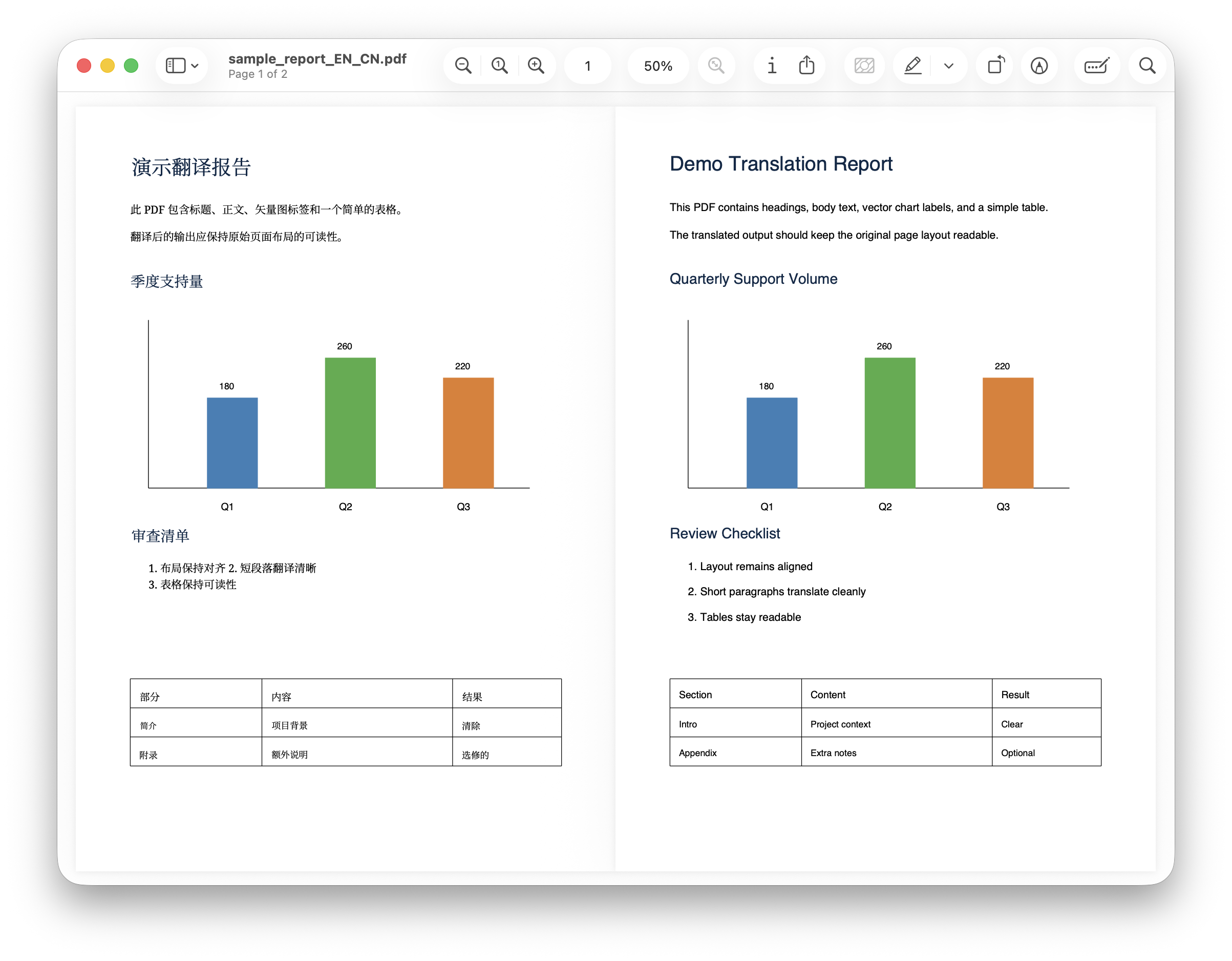
Markdown 和 TXT 的双语输出会按段落交错排列。这个形式很适合审校,因为你可以直接看到每段原文下面对应的译文。

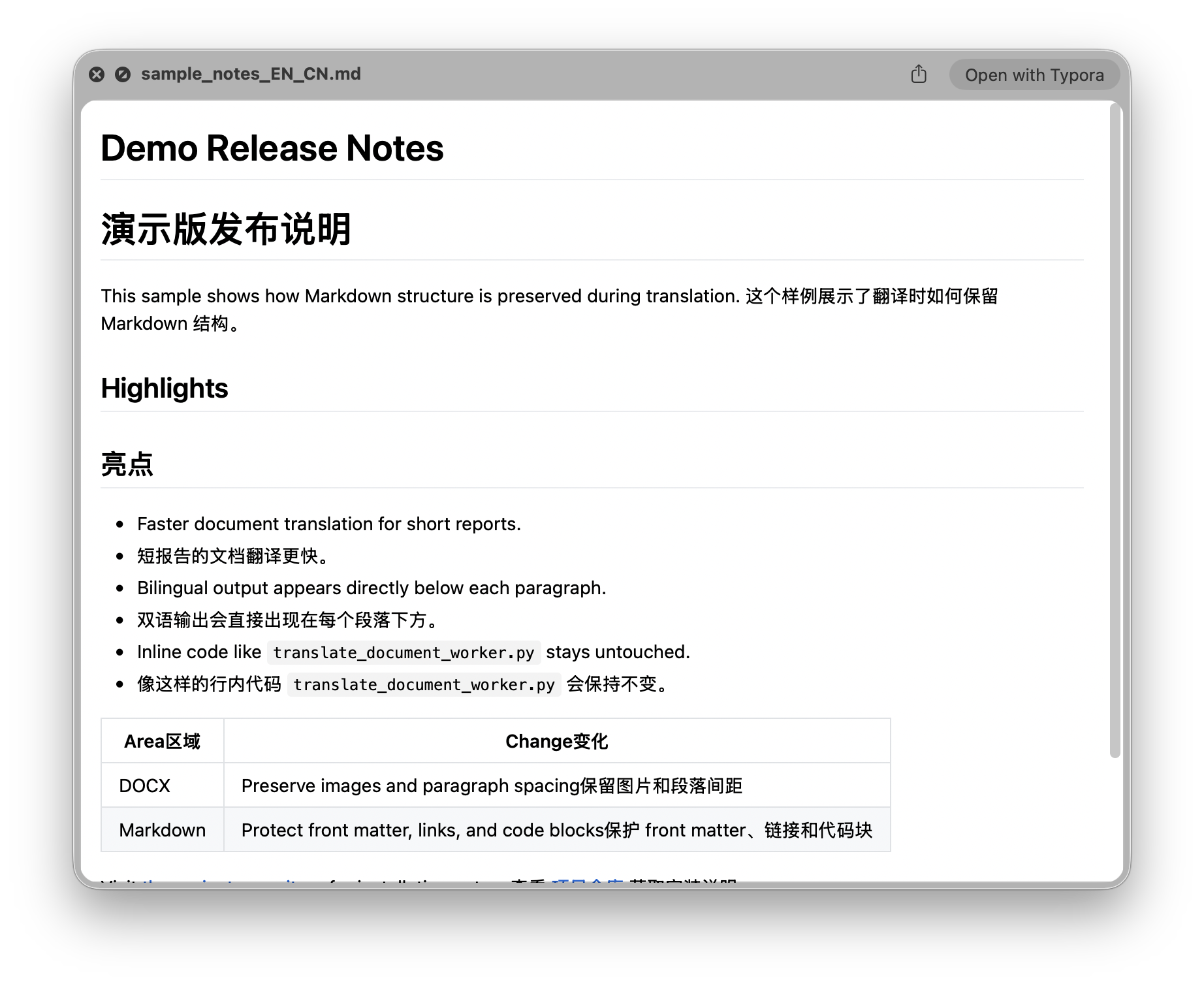
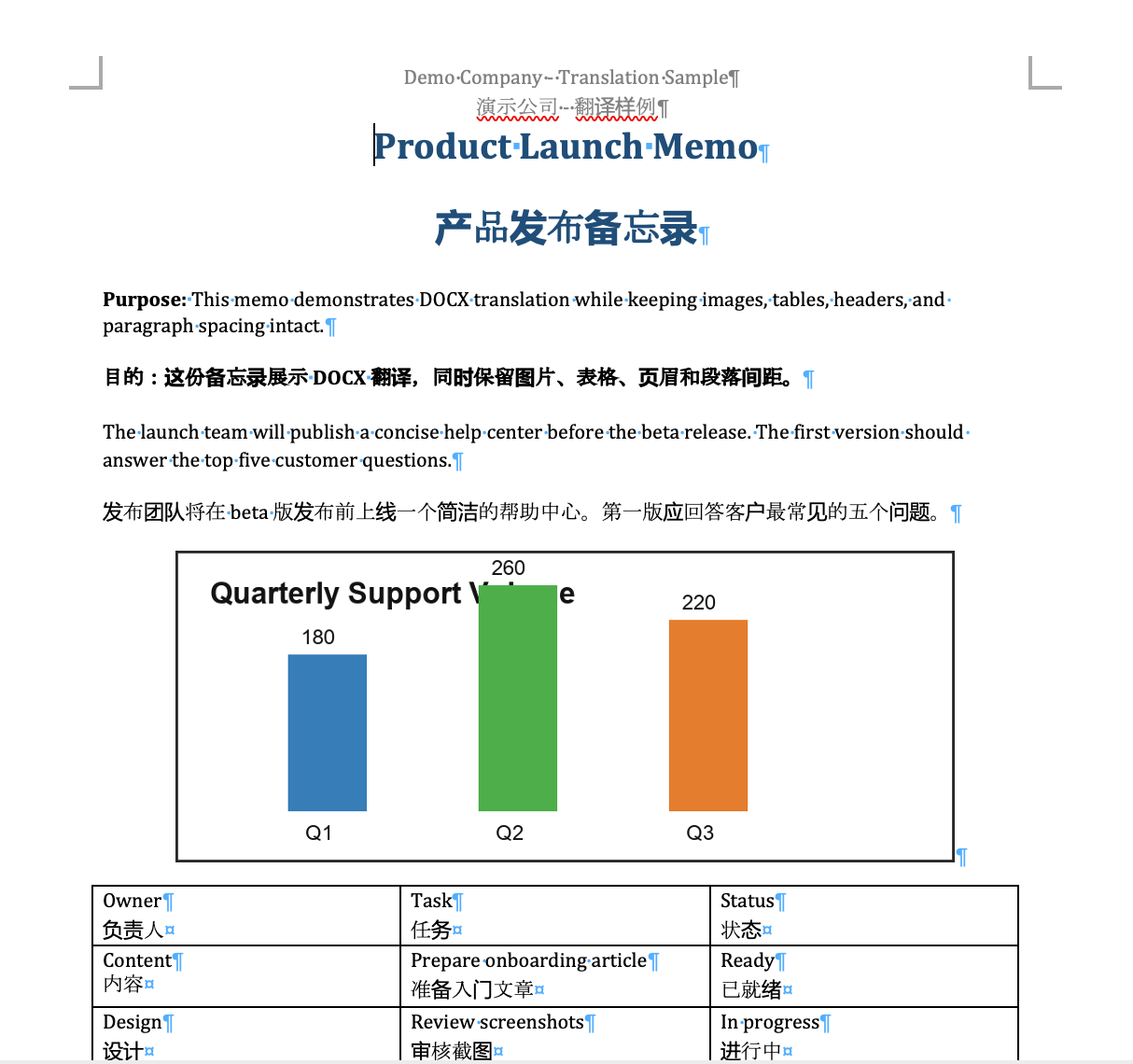
DOCX 的双语输出会在原段落后插入译文段落,同时尽量保留文档里的图片、媒体引用和原有结构。
图片翻译则可以走 macOS Vision OCR 的轻量路径:识别图片里的文字,翻译后再把译文画回检测到的文本区域。它适合截图、图表、幻灯片这类相对干净的图片。

翻译引擎与隐私选择
文本翻译部分目前支持 Google、Bing 的网页端点,也支持本地 Ollama 适配器。
Google 和 Bing 的方式胜在方便,但它们不是官方付费 API,可能遇到限流,也可能因为上游行为变化而失效。如果是敏感文档,我更建议使用本地 Ollama 后端,或者把翻译适配器替换成正式的官方 API。
这个项目刻意把“文件结构处理”和“翻译后端”分开,后续要换引擎会比较直接。
安装方式
先安装 Python 依赖:
|
|
如果要翻译 PDF,需要单独安装 pdf2zh-next:
|
|
如果要使用 macOS Finder Quick Actions,可以运行:
|
|
命令行用法
翻译 TXT、Markdown 和 DOCX:
|
|
用 macOS Vision OCR 的轻量方案翻译图片:
|
|
转录音频或视频,并翻译转录稿:
|
|
使用时要注意什么
这是一个面向日常自动化的工具,不是“所有复杂文档都能完美翻译”的承诺。
DOCX 目前覆盖正文、页眉、页脚、脚注、尾注和批注等常见内容。像 SmartArt、嵌入对象、公式、复杂文本框这类 Word 高级结构,仍然需要更多测试。
图片里的 simple-macos 引擎适合干净截图、图表和幻灯片。它不是 AI 修图或智能重绘。如果背景复杂,或者是漫画这类场景,更适合接入可选的 manga-image-translator。
如果你的翻译工作经常在 PDF、Word、Markdown、截图和录音之间来回切换,这个项目至少能把入口统一起来,让常见任务不用再散落在一堆临时脚本里。
相关阅读
- 如果你更关心纯文本的本地 AI 翻译和隐私,可以看 Mac-Lite-Translator:基于 Google Gemma 的 Mac 本地翻译工具。
- 如果你经常处理多语言写作,也可以看 ABC Custom Keyboard:一把美式键盘覆盖多语言写作和学术符号。